Financial Data Cross-Referencing & Big Data Processing
with Python / PySpark
ℹ️ Important Information
🎯 Project Goals
The objective is to design a tool for cross-referencing user financial information (debts and assets) from various data sources: internal debt files and credit files. Initially limited to a pilot geographic area, the project now targets nationwide deployment.
🗂️ Functionality & Data Processed
- Aggregates and cross-references multiple types of financial and administrative data from internal and external systems.
- Main sources: specific credit and debt files; additional sources can be integrated later.
- An interactive data visualization interface will be developed for data exploration.
🛠️ Technical Objectives
- Data Access & Processing: Implement pipelines to retrieve, enrich, and cross-reference financial data.
- Visualization: Deliver a central dataset enabling dashboard development for detecting atypical situations or regularization opportunities at a national scale.
- 3 Debt files (one per application)
- 3 Credit files (one per application)
- User reference file for complementary user information
- Company reference file for company-related details
- Languages used: Python & PySpark
📋 Solution Workflow
- Data Collection and Preparation
- Data Merging, Deduplication, and Cross-checking
- Enrichment, Cleaning, and Export for Dashboarding
- Processing High-Volume Data using PySpark
1️⃣ Part 1: Data Collection and Preparation
The aim is to gather and prepare all financial data sources (debts and credits) from different internal applications for further cross-referencing.
- Load debt and credit files separately; each comes from a distinct application (e.g., different zones or business units).
- Mark user presence in each source (useful for identifying multi-source users).
- Rename columns (except the main identifier) to avoid collisions during merges.
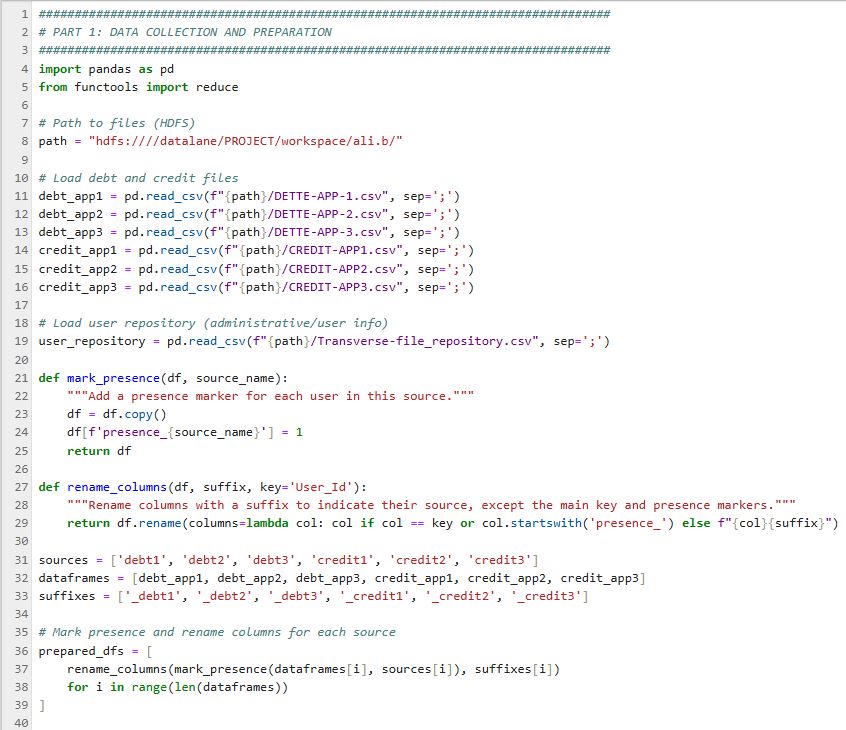
2️⃣ Part 2: Data Merging, Deduplication, and Cross-checking
Cross-reference user information across all sources, identify users present in multiple files, and aggregate key financial data.
- Merge all data sources using the user identifier (User_Id) for a complete user overview.
- Create an indicator counting the number of sources where a user appears—helps flag risk or opportunity profiles (multi-source presence).
- For each key field (amount, status, type, etc.), keep the first non-null value found among all sources for a synthetic, actionable view.
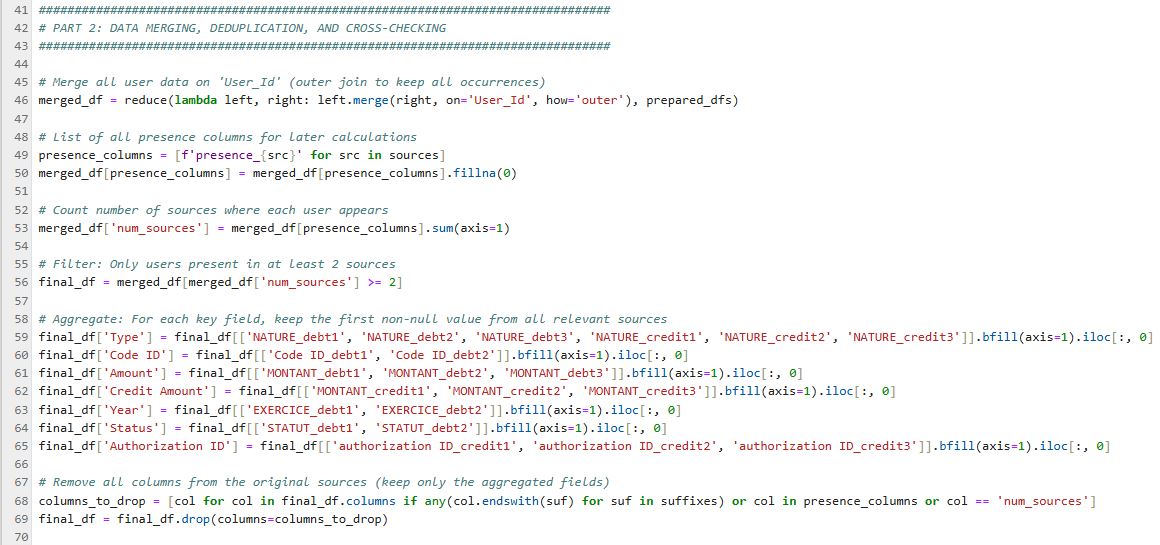
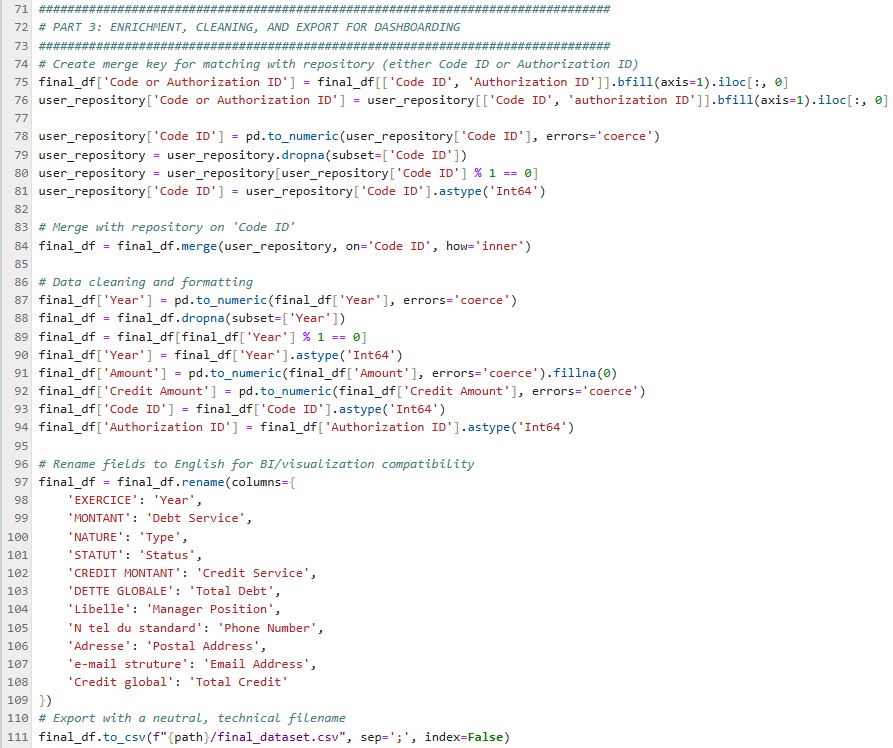
3️⃣ Part 3: Enrichment, Cleaning, and Export for Dashboarding
Enrich the dataset with administrative reference data, clean and harmonize fields (types, translations), and prepare the file for use in BI tools or national dashboards.
- Create a join key (e.g., Code ID or Authorization ID) linking financial and reference information.
- Harmonize data types and translate all field names/titles into English for easy exploitation in BI, dataviz, and national reporting.
- The final exported file centralizes all data needed for anomaly detection or regularization actions.
4️⃣ Part 4: Processing High-Volume Data Using PySpark
The Transverse-statistical_file.csv is too large for classic Python/pandas processing on standard machines (RAM limits). This step uses PySpark—a distributed framework designed for big data.
- Load and enrich the consolidated dataset with the large statistical file, joining by user identifier.
- Calculate total debts and credits per user (aggregates).
- Classify records (Debt / Credit / Unknown).
- Build billing addresses from multiple address fields.
- Clean missing values.
- Export the finalized results, ready for BI integration.
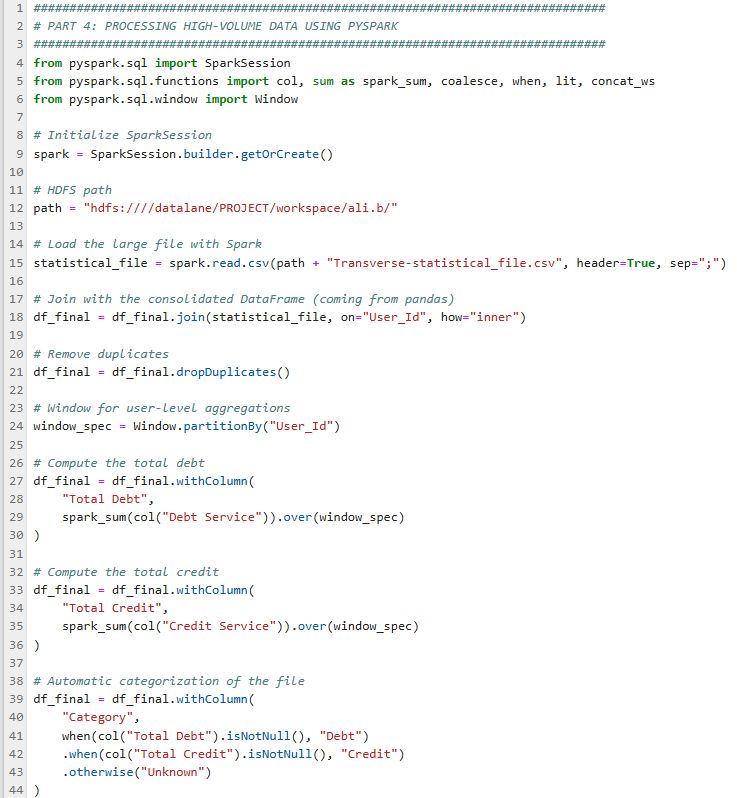
- PySpark join on User_Id to enrich the final DataFrame with all statistical info.
- Per-user calculations using Spark windows (total debts, total credits).
- Dynamic categorization by presence of debts/credits.
- Complete billing address creation (concatenation of several address fields).
- Column renaming to harmonize all datasets.
✅ Summary & Key Learnings
- Collection & Preparation: Import, traceability, and renaming of raw data to ease multi-source merging.
- Cross-referencing & Aggregation: Smart user-based merging, key field aggregation, and profiling for risk/opportunity identification.
- Enrichment & BI Prep: Adding reference info, type harmonization, English renaming, and export for nationwide BI deployment.
- Big Data Processing (PySpark): PySpark for processing large statistical files, advanced per-user calculations, and export of enriched data for large-scale analysis.